Chrome的文件类型识别功能
Chrome浏览器不仅是一款功能强大的网络浏览器,还具备许多实用的内置工具和功能。其中,文件类型识别功能尤为重要,能够帮助用户快速准确地识别各种类型的文件,从而提高工作效率和数据安全性。本文将详细介绍如何在Chrome浏览器中使用这一功能,包括OCR技术的应用以及相关设置。

一、什么是文件类型识别?
文件类型识别是指通过分析文件的内容或扩展名来确定其类型的过程。在数字化时代,准确识别文件类型对于数据管理、安全检查、内容检索等方面都非常重要。传统的文件类型识别方法通常依赖于文件扩展名(如.pdf、.jpg等),但这种方法并不总是可靠,因为文件扩展名可以被篡改。现代浏览器如Chrome则采用更先进的技术,如OCR(光学字符识别),来提高识别的准确性。
二、Chrome中的OCR功能
OCR是一种通过图像处理技术将图片中的文字内容转换为可编辑文本的技术。Chrome浏览器内置了PDF阅读器的OCR功能,可以将扫描的PDF文件中的图片内容转换为可搜索的数字文本。
1.启用OCR功能:
-确保你的Chrome浏览器是最新版本。如果不是,请访问[Chrome官方网站]下载并安装最新版本。
-打开Chrome浏览器,点击右上角的三个垂直点菜单按钮,选择“设置”。
-在设置页面中,点击左侧的“隐私与安全”选项。
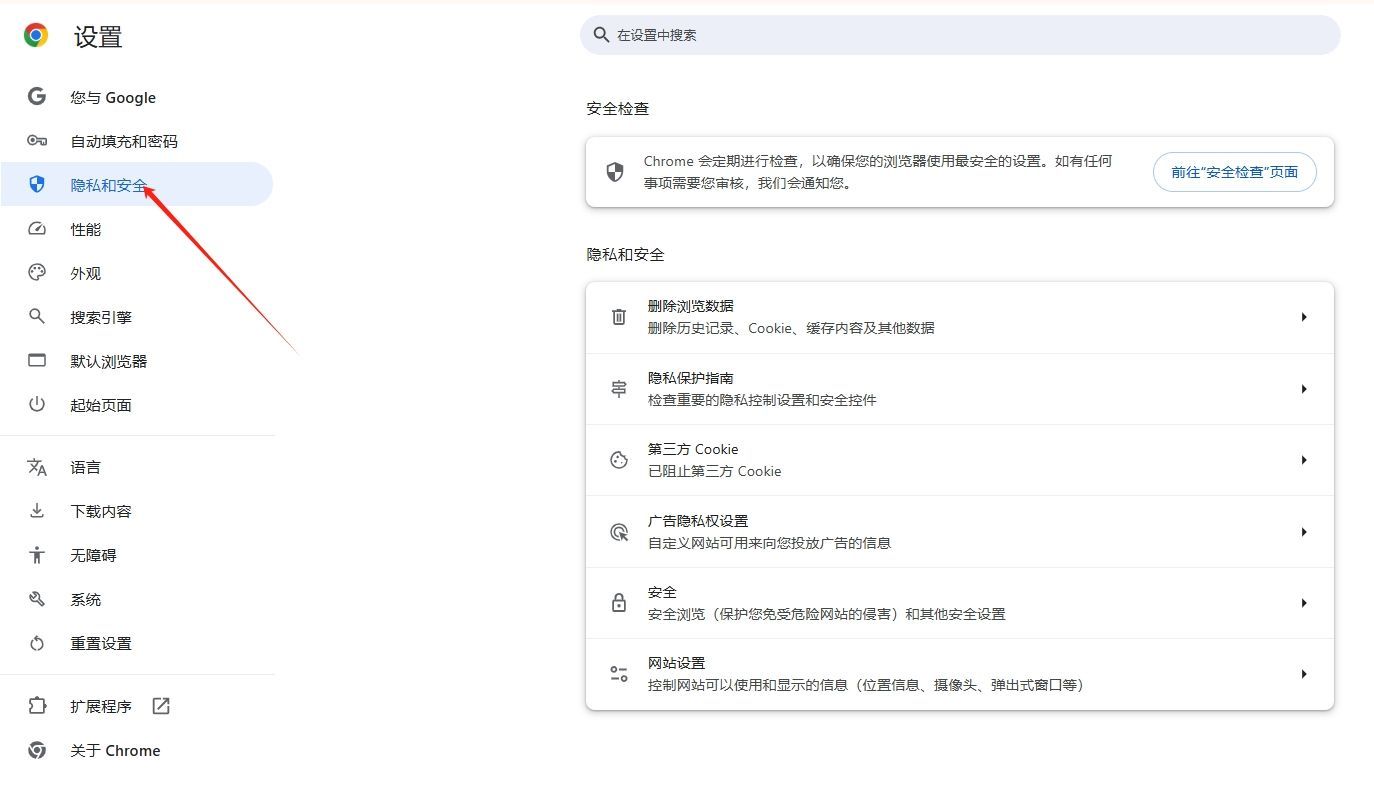
-向下滚动找到“网站设置”,点击进入。
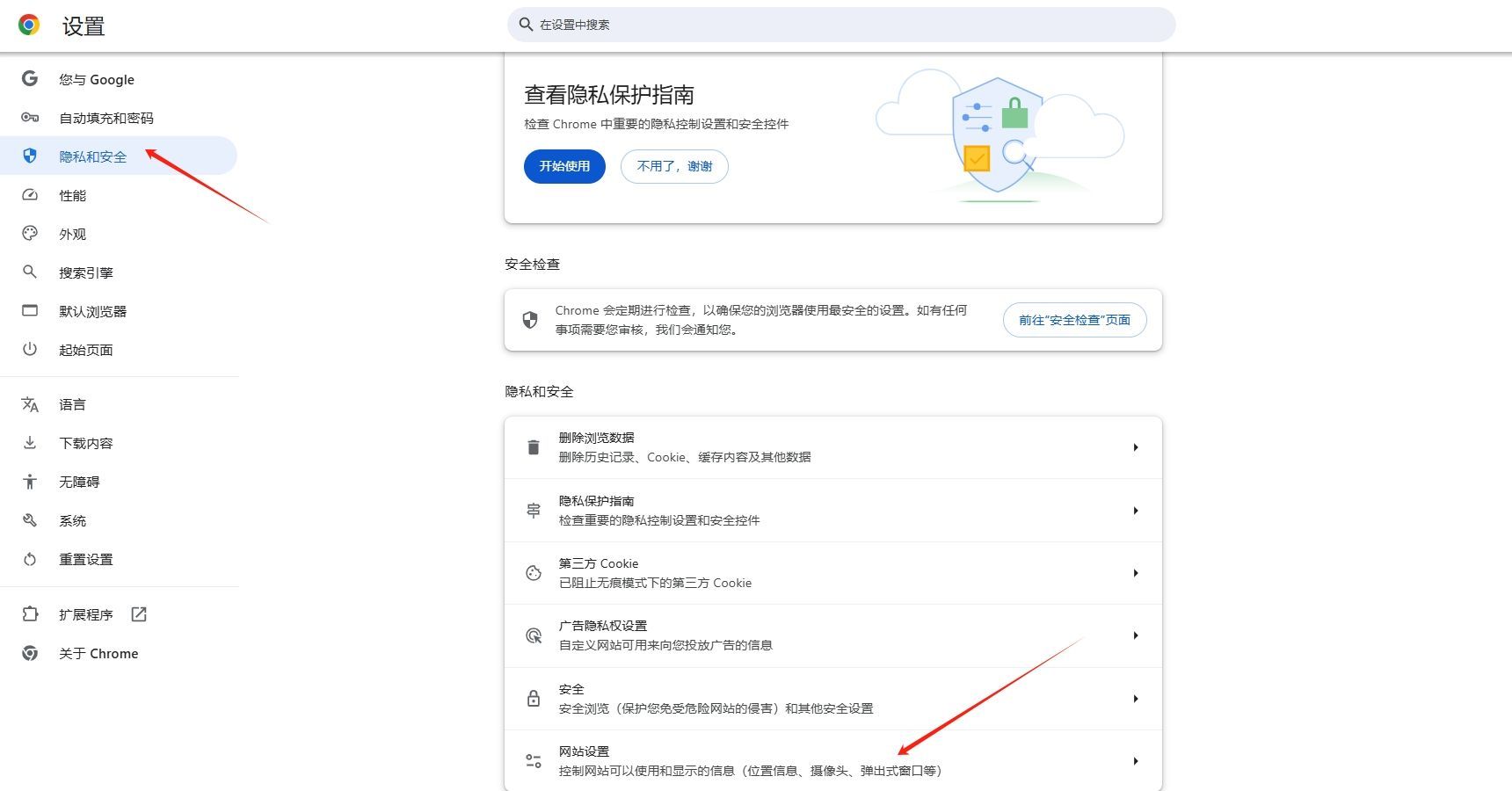
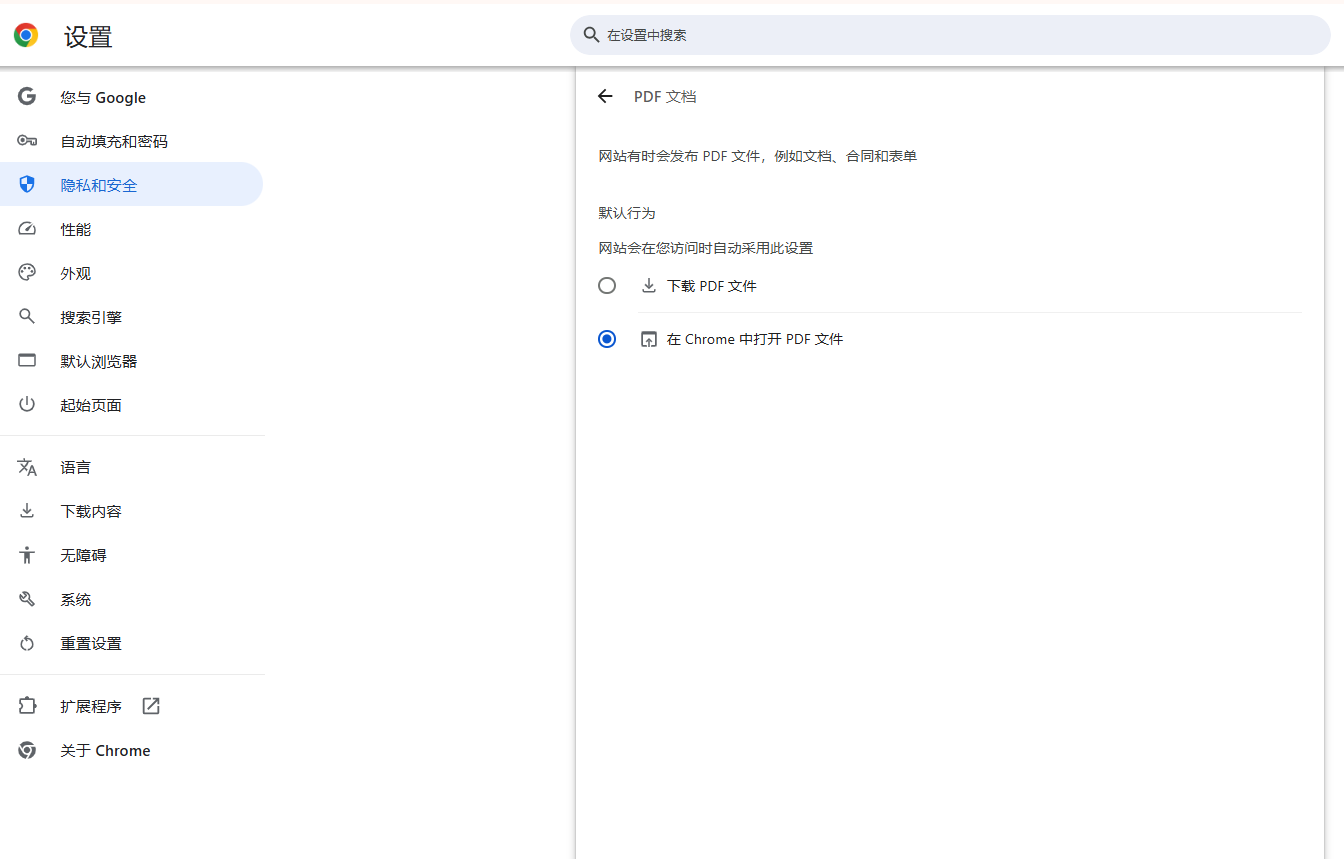
-在网站设置页面中,找到“PDF文档”选项,确保其设置为“允许”。
2.使用OCR功能:
-打开一个包含扫描图片的PDF文件。你可以将文件拖放到Chrome窗口中或使用菜单中的“文件”-“打开”选项。
-Chrome会自动尝试将图片中的文字内容转换为可编辑的文本。如果OCR功能正常工作,你可以通过搜索功能查找特定关键词,或者复制转换后的文本内容。
3.多页扫描与OCR:
-如果需要一次性扫描多页文件,可以使用Chrome的实验性功能。目前,谷歌正在开发一项名为“多页扫描”的实验性Flag,未来可能会允许用户一次性扫描多个页面并将其打包成一个整齐的PDF文件。不过,这项功能尚未对所有用户开放,但你可以关注Chrome的更新日志以获取最新信息。
三、使用Magika进行高级文件类型识别
除了内置的OCR功能外,Chrome还可以借助外部工具如Magika来增强文件类型识别能力。Magika是一款由谷歌开源的高效文件类型识别工具,基于深度学习模型,能够更准确地识别复杂或模糊的文件类型。
1.安装Magika插件:
-访问Chrome网上应用店或其他可信来源下载并安装Magika插件。
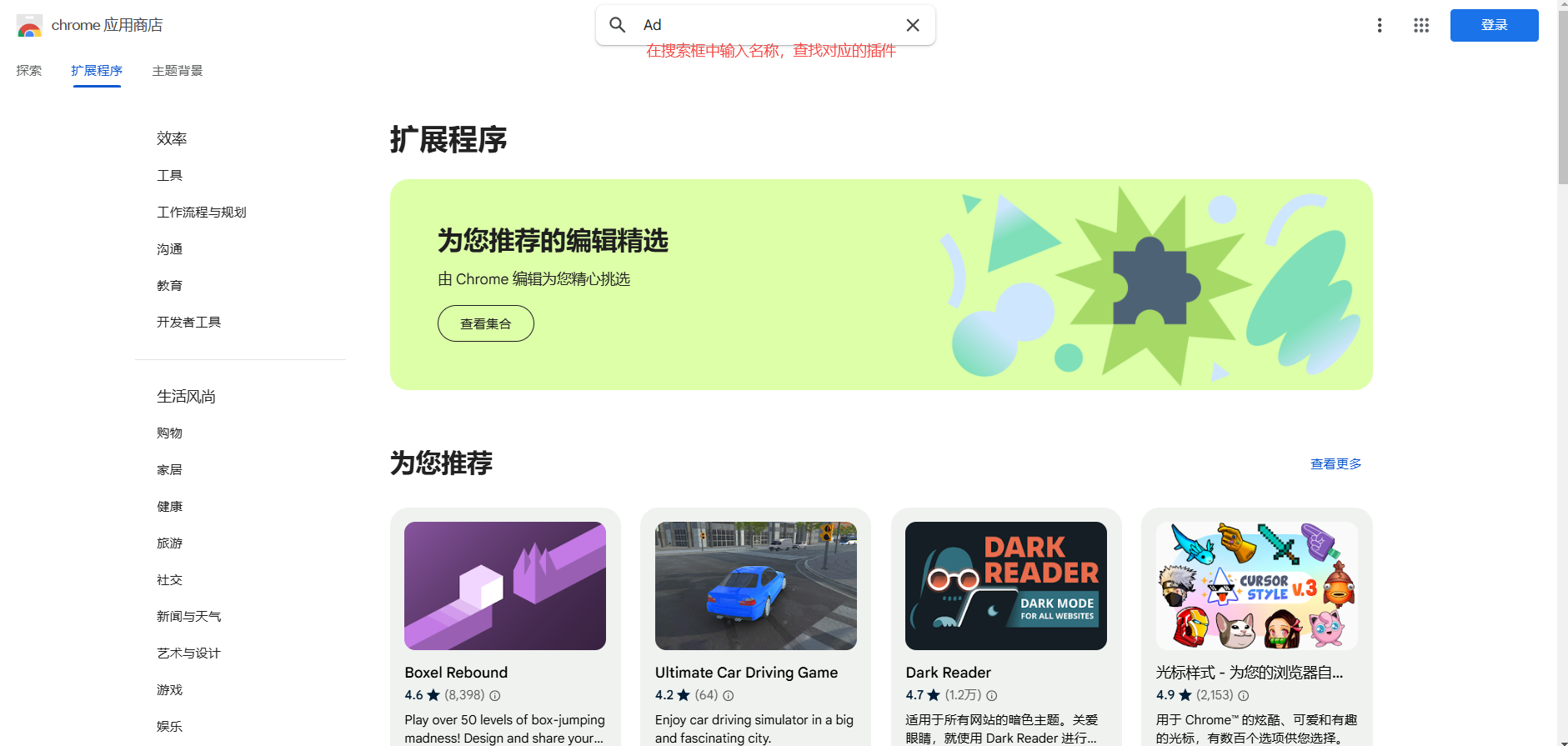
-安装完成后,重启Chrome浏览器以使插件生效。
2.使用Magika识别文件类型:
-安装完成后,Magika会自动集成到Chrome的右键菜单中。
-当你需要识别某个文件的类型时,只需在文件上点击鼠标右键,选择“使用Magika识别文件类型”。
-Magika会迅速分析文件内容并给出识别结果。
3.Magika的优势:
-高度准确:采用深度学习模型,无论文件类型有多复杂或模糊,都能准确识别。
-节省时间:自动且快速地识别大量文件,节省人工分类的时间。
-学习能力强:能够自动学习和适应新出现的文件类型。
-易于集成:提供友好的API接口,可以轻松集成到其他系统或应用中。
-安全性高:只读取文件内容进行识别,不会修改或存储文件,保证文件的安全性。
四、总结
Chrome浏览器提供了强大的文件类型识别功能,特别是通过OCR技术和外部工具如Magika的结合使用,可以极大地提高工作效率和数据安全性。无论是日常办公中的文档处理还是专业的数据分析工作,掌握这些技能都将为你带来便利和优势。希望这篇教程能帮助你更好地利用Chrome的文件类型识别功能,提升你的数字生活体验。